EPiServer’s DXC cloud based Azure platform as a service provides the availability and scalability necessary to auto scale enterprise level high transaction applications. DXC has bundled within it’ set up an Azure Storage Account used for Blob Storage and a Service Bus used for managing events such as invalidation of cache between instances. Once your application is deployed to DXC, it just works and let’s the partner concentrate on delivering a robust quality build.
An Azure Storage Account comes with the following types of storage but do note that while these are technically within the DXC storage account they are not yet exposed for integration purposes.
- Queue https://azure.microsoft.com/en-gb/services/storage/queues/
- Table https://azure.microsoft.com/en-gb/services/storage/tables/
- File https://azure.microsoft.com/en-gb/services/storage/files/
However that shouldn’t mean that we can’t use an Azure Storage account to build our applications. Even if these services are not exposed within DXC, you can set up a Storage Account under another Azure subscription as the cost even under a large volume of integrations is tiny: https://azure.microsoft.com/en-us/pricing/details/storage/queues/
Azure Queues
Azure Queue Storage is for storing messages in the cloud to be exchanged between components of systems. Typically a “producing” system will create a message which is to be processed by the “consumer”.
Azure Queue’s are well used in an EPiServer application to decouple the logic around integrating with third party systems from our EPiServer code base. Once solution design is complete we can treat the EPiServer application which pushes the message as a separate code base to the delivery application. This approach has loads of benefits:
Maintainability
If there are issues with an integration, developers no longer have to debug the web application to get to the bottom of it. They can simply check the messages entering the queue, verify the data in the queue and then the effort can instantly focus on the pushing of the message or delivery application components.
Managing both applications in separate deployment pipelines also mean we don’t have to test the web application code base if we are updating an integration and vice versa.
Scalability
Azure Queue’s are insanely scalable coping with up to 20,000 messages per second! All our EPiServer application has to do is push the message.
Error Tracking
When the delivery of a message fails, Azure Queue’s will be default retry 5 times. However both the retry attempts and time between retries can be configured. When a message fails past the set thresholds it enters a “poison” queue where it can be viewed and have additional error handling implemented. I’ll touch on this further down the article.
Quality
In addition to each of the reasons above, having separate application in separate CI deployment pipelines gives us the foundation to write independent sets of robust unit tests. Done well, we will find mistakes in code long before they get deployed a live environment.
Time To Market
After initial solution design is complete, you can have separate independent development teams working on the web and integration applications increasing velocity and hopefully getting us live earlier! Hiring managers also love it as they do not necessarily need new hires to have EPiServer skills to make an impact on a project.
Let’s see some Code!
Putting a message on a queue
In this example we’ll put a very simple Contact on a queue which can will later be synced to an Email Marketing Platform.
First create your storage account on your subscription as documented by Microsoft: https://code.visualstudio.com/tutorials/static-website/create-storage
If you like, you can download Azure Storage Explorer to inspect your Storage account:
The first step in our EPiServer application is then to install the following nuget package: https://www.nuget.org/packages/WindowsAzure.Storage/
On events such as a new user registering for your site, you can then simply push the relevant data to a queue and from that point on the web application will have not responsibility for the delivery of the package to the third party platform. Pushing a message to a queue is very simple as illustrated in this sample where i push a json serialised contact model.
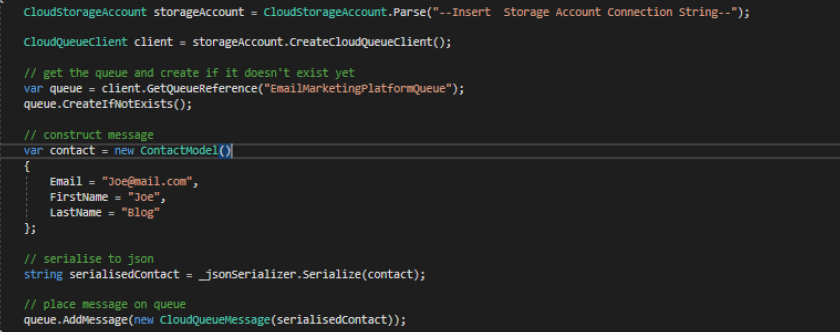
Introducing Azure Functions
Now that we have a message saved in an Azure Queue, we need to process it and send to our third party application.
Azure Functions is an event driven, serverless computing service that extends the existing Azure platform allowing us to implement code triggered by events occurring in Azure. Functions can also be extended to third party service and on-premises systems but in this post we’re focused on Azure.
Using Visual Studio we can simply add a new Azure Functions project to our solution.
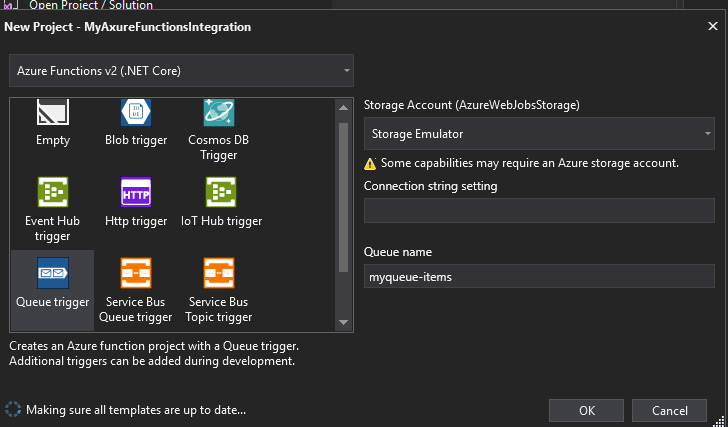
On the set up screen we can choose a Queue Trigger template setting the “ConnectionString” and “Queue name” to the same values as in the previous step.
This will scaffold a very simple function:
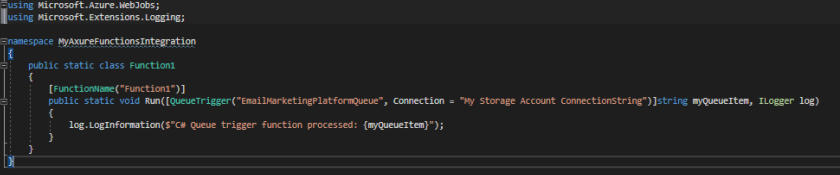
Every time a message is inserted on our “EmailMarketingPlatformQueue” queue the function will get executed and from here we can implement the integration with our third party system.
Azure Functions Pro Tips
This library gives you Dependency Injection capabilities you will require to use a test driven approach to your development, :
https://github.com/BorisWilhelms/azure-function-dependency-injection
What if it fails, logging retries?
By default, a queue trigger will be tried 5 times before it then inserts the message into a “poison” queue.
You can configure both the number of retry attempts and the time between retries in the host.json file which is added to your solution in the VS set up.
https://docs.microsoft.com/en-us/azure/azure-functions/functions-bindings-storage-queue#host-json
Alternatively you can set the retry policy programmatically as you push messages to a queue.
If you want to do extra processing when a message enters the poison queue, you can simply write a new Azure Function to be triggered on that event.
Suggestions for DXC
I would love to see this approach supported out of the box in the DXC and these are the two things i would like to see happen:
- Support for Deployment of Functions to DXC
- Future versions of the EPiServer.Azure package to provide methods to push data to other Azure Storage services
I don’t know if this is on the roadmap for DXC and if it isn’t I trust there are good reasons behind that. However in the meantime, running your own Storage account can repay the small cost over time.



